动荡的美国大选、极端天气事件和新冠肺炎继续考验着人们的决心和韧性。人工智能、合成生物学、超大规模计算、机器人和太空任务等前沿技术也正在挑战着我们对人类潜力的假设。
在全球封锁状态下,人们学会了如何在餐桌上工作,如何在空闲的房间里做决策,如何远程互相支持。但是这种改变才刚刚开始,人们比以往任何时候都更需要掌握技术趋势的潜在近期和长期影响。
近日,未来今日研究所(Future Today Institute)发布了《2021 年科技趋势报告》,报告分析了多个行业的近 500 种科技趋势,并对未来一年将影响商业、政治、教育、媒体和社会的战略趋势做出了具体的描述。正如这份科技趋势所述,未来的世界将深受人工智能、5G、区块链等技术的影响。

图 | 2021 科技趋势报告封面 (来源:FTI)
20 世纪 20 年代始于混乱,第一次世界大战和西班牙大流感导致了灾难性破坏,但是无线电、冰箱、真空吸尘器、移动装配线和电子动力传输等技术奇迹产生了新的增长。
这些场景与当今世界存在着太多惊人的相似之处。新的危机中,人工智能等一系列科技的力量带动了新的发展。由于人工智能现在已经被应用于大多数行业,在新版的科技趋势报告中,FTI 首先介绍了人工智能领域的发展趋势。
趋势报告内容表明,人工智能正以惊人的速度从学术界转向企业。同时,以亚马逊网络服务、Azure 和谷歌云为代表的低代码和无代码产品,将渗透到日常生活中,使人们能够创建自己的人工智能应用程序,并轻松地部署它们。
但是从另一方面看,人工智能社区仍然使用封闭源代码模式运行。研究人员不愿意公布他们的完整代码,导致透明度和再现性降低,问责制度模糊不清。
研究报告还对中国的人工智能发展现状做出了一系列分析。分析认为,中国已经成为人工智能研发强国,并且明确指出中国日益增长的人工智能力量不是军事、经济和外交等方面的威胁。
除了上述这些内容,报告还从多方面展示了人工智能领域未来的发展趋势。无论是对于人工智能企业、人工智能研究者,还是人工智能学习者,这都是一份比较详尽的报告。
限于篇幅,学术头条精选了报告中关于人工智能的部分内容进行翻译,希望对读者有参考价值。报告更多亮点及全文,可在文末查看。


图 | 人工智能科技趋势总览
0. 人工智能综述
0.1 关键见解
人工智能代表了计算的第三个时代,通常它被定义为机器执行认知功能的能力与人类一样好或比人类更好。这些功能包括感知、学习、推理、解决问题、理解上下文、做出推理和预测以及锻炼创造力。
0.2 突破性影响
突破性研究、业务用例、数据爆炸式增长以及计算能力和存储的改进的融合正在推动人工智能的进步。从 2021 年到 2027 年,全球人工智能市场预计将以 42.2% 的年复合增长率继续增长。
0.3 超级玩家
Broad Institute、Clarifai、Clearview AI、DeepMind、Disperse、Graphcore、HiSilicon Technologies、Kasisto、LabGenius、Mohamed bin Zayed University of Artificial Intelligence、Niantic、Nvidia、OpenAI、OpenMined、Persado、PolyAI、Recursion、SenseTime、Scale AI、Syntiant。
0.4 机器学习
机器学习使用数据对如何实现既定目标做出预测和建议。机器学习的类型包括有监督的、无监督的和强化的。在监督学习中,算法使用训练数据来学习已建立的参数之间的关系。在无监督学习中,数据被提供给没有特定输出参数的算法。在强化学习中,一种算法通过重复运行计算来学习执行一项任务,以此来实现一个既定的目标。
0.5 深度学习
深度学习是机器学习的一个相对较新的分支。程序员使用特殊的深度学习算法以及大量的数据来实现系统的自主学习。深度学习的出现意味着越来越多的人类过程将被自动化。常见的深度学习类型包括卷积神经网络、递归神经网络、变压器神经网络和生成对抗网络 (GANs)。。
卷积神经网络 (CNN) 是多层的,具有卷积层、汇集层和完全连接层。每个人使用数据执行不同的任务,输出是分类。递归神经网络 (RNNs) 是多层神经网络,在输入层、隐藏层和输出层之间移动和存储信息,多用来为预测建立序列数据模型。生成对抗网络 (GANs) 是无监督的深度学习系统,由两个相互竞争的发生器和鉴别器组成。变压器是一种神经网络架构,当单词出现在特定的上下文中时,它会学习单词的含义。
0.6 强弱 AI
人工智能有两种 — 弱 (或 “狭义”) 和强 (或 “广义”),没有单一的标准来区分弱 AI 和强 AI。这对于研究人工智能发展的研究人员和必须对人工智能做出决策的经理来说是有问题的。事实上,我们已经开始看到现实世界中运行人工智能的例子。DeepMind 的一些项目已经证实了人工智能在某些领域比人类做的更好。虽然我们还没有看到拟人化的人工智能走出 DeepMind 的实验室,但我们应该把这些项目视为今天的弱人工智能和明天的强人工智能之间漫长过渡的一部分。
1. AI 与企业
1.1 MLOps 的兴起
2020 年,一些增长最快的 GitHub 项目是 MLOps,即处理工具、基础设施和操作的项目。展望未来,MLOps 将描述一套结合机器学习、传统开发和数据工程的最佳实践。
1.2 低代码或无代码机器学习
机器学习正在转变,因为新平台允许企业利用人工智能的力量来构建应用程序,而不需要知道具体的代码。
1.3 网络规模的内容分析
由于先进的自然语言处理收集和分类,挖掘非常大的非结构化数据集现在变得更加容易。经过识别关键字的训练,特殊的算法可以快速地对信息进行排序、分类和标记。
1.4 模拟同情和情感
人工智能现在可以测量表示一个人情绪状态的生物标记,如焦虑、悲伤或眩晕。精确检测人类情感具有挑战性,但是拥有足够大数据集的公司正在开发精确的模型。

图 | 通过测量某些生物标记,人工智能可以检测人们的情绪并做出相应的反应
1.5 人工情感智能
研究团队正在教授机器无条件的爱、积极的倾听和同理心。在未来,机器将令人信服地展示人类的情感,如爱、快乐、恐惧和悲伤。这项技术最终可能会出现在医院、学校和监狱,为病人、学生和囚犯提供情感支持机器人。
在我们日益紧密联系的世界里,人们感到更加孤立。未来与大规模精神健康危机作斗争的政府可能会转向情感支持机器人来大规模解决这个问题。
1.6 无服务器计算
AWS、阿里巴巴云、微软的 Azure、谷歌云和百度云正在为开发人员推出新的产品,目标是让广大人工智能初创企业更容易、更实惠地将他们的想法推向市场。一些其他企业也正在加入这个领域。
1.7 云中 AI
人工智能生态系统中的企业领导者一直在竞相获取人工智能云共享,并成为远程服务器上最值得信任的人工智能提供商。企业客户可能会坚持他们最初的供应商,因为机器学习系统随着时间的推移,收集的数据越来越多,变得越来越好。
1.8 边缘计算
物联网及其数十亿台设备,加上 5G 网络和不断增强的计算能力,使得边缘大规模人工智能成为可能。在设备上直接处理数据在未来对医疗保健、汽车和制造应用非常重要,因为它可能更快、更安全。
1.9 先进人工智能芯片
神经网络长期以来需要大量的计算能力,需要很长时间来训练,并且依赖于消耗数百千瓦功率的数据中心和计算机。这一切都开始改变了。包括华为、苹果、微软、Facebook、Alphabet、IBM、英伟达、英特尔和高通在内的大型科技公司,都在开发新的系统架构和 SoCs,这意味着芯片更容易在人工智能项目中工作,并且应该保证更快、更安全的处理。

图 | 三星的下一代 Exynos 芯片将有一个 AMD 图形处理单元 (GPU)
1.10 数字孪生
数字孪生是现实世界环境、产品或资产的虚拟表示,用于各种目的。随着低代码和无代码系统变得越来越普遍,公司应该能够构建和部署数字孪生来模拟一系列广泛的过程,这将导致现代化进程的支出减少。
1.11 辨别真假
在过去的一年里,研究人员展示了人工智能是如何被用来编写如此优异的文本,以至于人类无法分辨它是否机器编写的。事实证明,人工智能也可以用来检测文本是何时由机器生成的,即使我们人类无法识别伪造的文本。
1.12 面向 ESGs 的自然语言处理
企业社会责任标准必须量化并明确表述,但衡量绩效可能很困难,因为涉及许多无形资产或抽象概念。自然语言处理正被用于识别、标记和分类来自各种来源的关于公司 ESG 声誉的文档。
1.13 智能光学字符识别
一个持续的挑战是让机器认识到我们在写作中表达自己的各种方式。光学字符识别 (OCR) 以固定的、可识别的格式工作。但是,光学字符识别通常不够智能,无法识别不同的字体、独特的符号或只针对一家公司的电子表格字段。研究人员正在训练人工智能系统识别模式,即使它们出现在不寻常的地方。
1.14 机器人过程自动化
机器人过程自动化 (RPA) 可以自动化办公室内的某些任务和过程,并允许员工将时间花在更高价值的工作上。这是企业中最常用的人工智能技术。
1.15 海量翻译系统
Facebook 的人工智能实验室使用从网络上自动收集的 75 亿对句子来训练该模型。FastText 语言模型识别语言,无监督学习模型根据句子的含义匹配句子。目标是提高同声传译。

图 | Facebook 推出了第一个不依赖英语数据翻译 100 种语言的人工智能模型 (来源:Facebook)
1.16 预测系统和站点故障
计算机视觉可以预测和识别物理位置的故障。高科技工厂、航空公司制造商和建筑工地使用图像识别系统来监控项目并自动警告问题。这是通过将现实世界的数据与数字双胞胎的数据进行比较来实现的。
1.17 人工智能责任险
当机器表现不好时,谁该受责备?例如,如果机器学习使一家公司容易受到向系统注入虚假训练数据的攻击者的攻击,会发生什么?这些问题可能会让一家公司面临诉讼风险。新的保险模式将有助于解决这些问题。保险商开始将人工智能纳入网络保险计划。
1.18 操纵 AI 以获得竞争优势
亚马逊、谷歌和 Facebook 在过去几年都因操纵搜索系统以优先考虑对公司更有利可图的结果而受到抨击。搜索算法的调整对互联网用户看到的内容有着重大影响,无论是新闻、产品还是广告。这也在一定程度上导致了针对这些公司的持续反垄断诉讼。
1.19 全球投资 AI 热潮
全球都在竞相资助 AI 研究和收购 AI 初创企业。根据国家风险投资协会的数据,2020 年第一季度,285 家美国 AI 初创公司筹集了 69 亿美元。随着 Covid 成为全球流行病,投资减少了,但包括苹果、谷歌和微软在内的科技巨头仍在收购 AI 公司。
1.20 算法市场
大型科技公司、初创公司和开发者社区使用算法市场来分享和销售他们的作品。2018 年,微软斥资 75 亿美元收购 GitHub,这是一个流行的开发平台,允许任何人托管和审查代码,与其他开发人员合作,并构建各种项目。AWS 拥有自己的市场,提供计算机视觉、语音识别和文本的模型和算法,其销售者包括英特尔、CloudSight 和许多其他公司。
1.21 100 年软件
与其他工程工具相比,传统软件的保质期短且不可预测。这导致令人头痛的问题和昂贵的升级,通常会导致停机。自 2015 年以来,美国国防高级研究计划局 (DARPA) 资助了一百多年来使软件可行的研究。这些系统将使用人工智能来动态适应环境和资源的变化。他们需要一种新颖的设计方法,使用人工智能来发现和显示应用程序的操作以及与其他系统的交互。
2. AI 与医疗、健康、科学
2.1 AI 加速科学发现
运行几个变量的实验通常需要对测量、材料和输入进行有条理的调整。研究生们可能会花费数百个乏味的小时反复进行小调整,直到找到解决方案,这是对他们认知能力的浪费。研究实验室现在使用人工智能系统来加速科学发现的过程。
2.2 AI 首次药物发现
新冠肺炎加快了人工智能在药物发现中的应用。一个国际团队在不到 48 小时的时间内合成了 2000 个分子的候选物,其中包括了一种 Covid 抗病毒药物 —— 这一过程可能需要人类研究人员一个月或更长时间。倡导者说,人工智能将使药物开发和临床试验更加有效,从而降低药物价格,为更个性化的药物铺平道路。

图 | AI 用于提高新药发现的速度和效率
2.3 AI 改善患者护理
新的医疗算法解决了美国的患者护理水平。不同的患者对症状的体验不同,他们的护理基于他们如何描述自己的症状以及医生如何解释这些症状。研究人员正在训练深度学习模型,并发现病人护理中的差距。
2.4 AI 在医学影像中的应用
放射学家和病理学家越来越依赖人工智能来帮助他们进行诊断医学成像。到目前为止,大多数获得批准的设备都增强了检查图像和进行诊断的过程。但是新兴的自主产品正在进入临床环境。
2.5 自然语言处理算法检测病毒突变
自然语言处理 (NLP) 算法通常用于文本、单词和句子,被用来解释病毒的遗传变化。蛋白质序列和遗传密码可以使用自然语言处理技术来建模,并且可以像在文字处理软件中写单词和句子一样进行操作。麻省理工学院的研究人员使用自然语言处理对病毒逃逸进行建模,通过在突变发生前使用这种模型,公共卫生官员可以制定策略,并潜在地防止新的病毒传播。
2.6 无测试诊断
多个研究院所的科学家们及健康科学公司 ZOE 共同开发一个应用程序来研究 Covid 症状并跟踪病毒的传播。它收集并使用人工智能来分析来自 400 万全球贡献者的数据,以发现新的症状,预测 Covid 热点,并最终预测 Covid 病例,而无需物理测试。
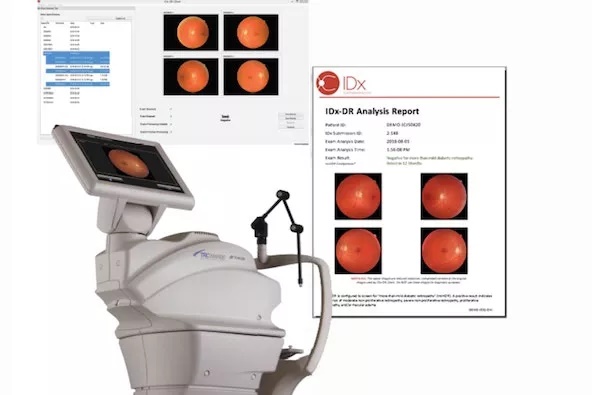
图 | 美国食品和药物管理局(FDA)批准第一个提供诊断决策的自主人工智能系统 IDx-DR。
2.7 蛋白质折叠
2020 年 11 月,DeepMind 的人工智能发布了一项重大公告:它成功地从蛋白质的氨基酸序列中确定了蛋白质的 3D 形状。预测蛋白质结构一直困扰着生物学家。AlphaFold 此前曾击败过其他团队,但它在去年的 CASP 上工作得如此之快、如此之准确,以至于它预示着这项技术将在不久的将来被其他科学家定期使用。
2.8 梦想交流
科学家发现了如何在清醒梦者之间建立双向沟通渠道。清醒梦者意识到自己睡着了,可以控制自己的梦境。并基于现有研究证明,做梦时有新的方式发送和接收实时信息。
2.9 思维探测
深度神经网络被用来使用无线信号分析情绪状态。研究实验室正在开发新技术来解读我们的思想。这有商业含义:人力资源部门可以决定员工对公司政策的真实看法,律师可以决定陪审员在案件中的倾向,房地产经纪人可以判断购房者的严重程度。
3. AI 与消费者
3.1 零用户界面
现代界面能够以更少的直接动作为我们做更多的事情,但仍然吸引着我们的注意力。零用户界面 — 承诺优先考虑这些决定,代表我们委托它们,甚至根据情况自主地为我们回答。许多这种无形的决策将在没有直接监督或来自人们的投入的情况下发生。
3.2 消费者级 AI 应用
已经出现了从专业研究人员使用的高度技术性的人工智能应用程序到面向精通技术的消费者的更轻量级、用户友好的应用程序的转变。新的自动化机器学习平台使非专家构建和部署预测模型成为可能。平台希望在不久的将来,我们将使用各种人工智能应用程序作为我们日常工作的一部分,就像我们今天使用微软办公软件和谷歌文档一样。
3.3 无处不在的数字助理
数字助理 (DaS) 使用语义和自然语言处理以及我们的数据来预测我们接下来想要或需要做什么,有时甚至在我们知道要问什么之前。新闻机构、娱乐公司、营销人员、信用卡公司、银行、地方当局、政治活动和许多其他人可以利用 DAs 来显示和传递关键信息。

图 | 阿里巴巴的天猫精灵使用自然语言处理
3.4 虚假娱乐深度
REFACE 是一个面部交换应用程序,可以将您的面部变形为名人的身体,并创建 GIF 在社交媒体上共享。Jiggy 是一个能让任何人跳舞的假货。就目前而言,它们都产生了看起来像被操纵过的图像和礼物。但是随着技术变得如此容易使用,我们还要多久才能区分真假?
3.5 个人数字双胞胎
许多初创公司正在构建可定制、可培训的平台,能够向你学习 —— 然后通过个人数字双胞胎在网上代表你。在不久的将来,包括健康和教育在内的一系列领域的专业人士可能会拥有数字双胞胎。
4. AI 与研究
4.1 封闭源代码
代码对于可再现性、可问责性和透明度非常重要,并且是推动更大的人工智能社区改进的关键。但是当学术研究人员发表论文时,他们通常不会包含所有的代码。给出的理由是:他们使用的代码与其他专有研究混合在一起,因此无法发布,这也正是企业的做法。
4.2 框架整合
谷歌的 TensorFlow 和 Facebook 的 PyTorch 是研究人员使用的两个流行框架,不同框架的相对流行通常反映了商业应用领域的趋势。在过去的四年里,Facebook 似乎取得了进展。在提到研究人员使用的框架的会议论文中,75% 引用了 PyTorch,161 位发表的 TensorFlow 论文比 PyTorch 论文多的研究人员中,55% 的人转向了 PyTorch。
4.3 培训模型的成本
训练一个模特要花很多钱。几个变量影响这些成本,所有这些成本在过去几年都有所增加。对于较小的研究团体和公司来说,成本是难以承受的。人工智能领域的一些人转而允许大型科技公司预先培训和发布大型模型。
4.4 自然语言处理基准
通用语言理解评估基准是用于训练、评估和分析自然语言理解系统的资源集合。人类基线分数为 87,自然语言处理系统在 2020 年 8 月增至 90.6,超过人类。SuperGLUE 基准是对更困难的语言理解任务、改进的资源和新的公共排行榜的新度量。预计到 2021 年底,这一新的基准也将被超越。

图 | SuperGLUE 将在 2021 年底被打破
4.5 机器阅读理解
对于人工智能研究人员来说,机器阅读理解一直是一个具有挑战性的目标,但也是一个重要的目标。MRC 使系统能够在筛选庞大数据集的同时阅读、推断意义并立即给出答案。2019 年,中国的阿里巴巴在接受微软机器阅读理解数据集 (简称 MARCO MS) 测试时表现优于人类。
4.6 AI 自我总结
新的 AI 模型可以总结科学文献,包括关于自身的研究。艾伦人工智能研究所 (AI2) 在语义学者中使用了这个模型,语义学者是一个人工智能驱动的科学论文搜索引擎,提供人工智能论文的简短摘要。这项工作之所以令人印象深刻,是因为它能够准确高效地压缩长论文。
4.7 无培训 AI
训练机器人做不止一件事是困难的,但是一种新的模型在一个游戏中让相同的机器人手臂相互对抗。这是多任务学习的一个例子,一种深度学习模式,在这种模式下,机器在进步的同时学习不同的技能。OpenAI 的模型允许机器人解决新的问题,而不需要再培训。
4.8 图形神经网络
图形神经网络 (GNNs) 构成了一种特殊类型的深度神经网络,它对图形作为输入进行操作。神经网络被用于检测气味 —— 在分子水平上预测气味 —— 以及广泛的化学和生物过程。例如,布罗德研究所的研究人员使用它们来发现没有毒副作用的抗生素化合物。
4.9 联合学习
联合学习是一种将机器学习推向边缘的技术。这是由谷歌研究人员在 2016 年推出的一个新框架,它使算法可以在不损害用户隐私的情况下使用手机和智能手表等设备上的数据。这个领域的研究急剧增加。
4.10 GP 模型
高斯过程是许多现实世界建模问题的黄金标准,尤其是在模型的成功取决于其忠实表示预测不确定性的能力的情况下。得益于神经网络的改进,全球定位系统变得更加精确和易于训练。
4.11 GPT-3 的影响
GPT-3 是由 OpenAI 在去年发布的,但是 AI 表现出强烈的反穆斯林偏见。在该模型的许多使用案例中,穆斯林暴力偏见始终如一地、创造性地出现。这是偏见如何潜入我们自动化系统的又一个例子。如果不加以控制,随着人工智能的成熟,它将在整个社会造成问题。
4.12 Vokenization
像 GPT-3 这样的模型是在句法和语法上训练的,而不是创造力或常识。人类以多层次、多维度的方式学习,因此一种称为 vokenization 的新技术通过将语言 “标记” 与相关图像进行上下文映射,来外推仅包含语言的数据。
4.13 机器图像完成
如果一个计算机系统可以访问足够多的图像 —— 比如说,数百万张 —— 它就可以修补和填充图片中的漏洞。这种能力对于专业摄影师以及每个想拍出更好自拍的人都有实际应用。随着这种技术变得司空见惯,将会有重大的偏见和其他陷阱需要克服。
4.14 使用单个图像的预测模型
计算机视觉系统变得越来越智能。神经网络可以从单一的彩色图像预测几何形状。这项研究有一天将使机器人能够更容易地在人类环境中导航 —— 并通过从我们的肢体语言中获取线索来与我们人类互动。零售业、制造业和教育背景可能尤其相关。
4.15 远程学习的无模型方法
梦想家是一种强化学习 (RL) 代理,它使用世界模型来学习长期预测,通过模型预测采用反向传播。它可以从原始图像中创建模型,并使用图形处理单元 (GPU) 并行从数千个预测序列中学习。这种新方法使用一个想象的世界来解决长期任务。
4.16 实时机器学习
人工智能面临的一大挑战是构建能够主动收集和解释数据、发现模式和整合上下文并最终实时学习的机器。对实时机器学习 (RTML) 的新研究表明,使用连续的数据流和实时调整模型是可能的。这标志着数据移动方式和我们检索信息方式的巨大变化。
4.17 自动机器学习
一些组织希望摆脱传统的机器学习方法,这种方法既耗时又困难,需要数据科学家、人工智能领域的专家和工程师。自动机器学习 (AutoML) 是一种新的方法:将原始数据和模型匹配在一起以揭示最相关信息的过程。谷歌、亚马逊和微软现在提供大量的自动产品和服务。
4.18 人机混合视觉
没有人类的帮助,人工智能还不能完全发挥作用。混合智能系统将人类和人工智能系统结合起来,以实现更高的准确性。微软研究人员提出了潘多拉,一套用于理解系统故障的混合人机方法和工具。潘多拉利用人类和系统生成的观察来解释与输入内容和系统架构相关的故障。
4.19 神经符号
研究人员正在研究使用神经网络将学习和逻辑结合起来的新方法,这种网络将通过符号来理解数据,而不是总是依赖人类程序员为他们排序、标记和编目数据。符号算法将有助于这一过程,这最终将导致一个健壮的系统,不总是需要一个人来训练。
4.20 通用强化学习算法
研究人员正在开发可以学习多项任务的单一算法。2020 年 1 月,DeepMind 发表了一项新的研究,表明强化学习技术如何可以用来提高我们对心理健康和动机的理解。
4.21 持续学习
目前,深度学习技术正在帮助系统学习以类似人类可以做的方式解决复杂的任务。他们需要一个严格的顺序:收集数据,确定目标,部署算法。这个过程需要人,并且可能很耗时,尤其是在需要监督训练的早期阶段。持续学习更多的是关于自我调节和增量技能的培养和发展,研究人员将继续推进这一领域可能的极限。
4.22 Franken 算法的扩散
虽然一个单一的算法可能很容易描述和部署,如预期的那样,算法系统一起工作有时会带来问题。开发人员并不总是事先知道一个算法将如何与其他算法一起工作。有时,几个开发团队在独立地处理不同的算法和数据集,一旦部署完成,他们只能看到彼此的工作。对于 Facebook 这样的大公司来说,这尤其具有挑战性,因为它们在任何给定的时间都有数十亿个算法在一起工作。
4.23 专有的、自主开发的 AI 语言
Python、Julia、Lisp 标志着人工智能生态系统的未来可能会出现分裂,这与当前 iOS/Android 的竞争或长期的 Mac/PC 战争并无不同。企业会发现在人工智能框架和语言之间切换越来越成本高昂和困难。
5. AI 与人才
5.1 AI 人才流失
人工智能研究人员从学术界流失到公司的速度惊人。原因很简单:薪酬待遇。顶尖学者获得丰厚的薪水和福利,他们可以在类似的终身环境中工作,这种环境是精心培养的,以代表他们在学术界的经验。今天挖墙脚的部门,可能会抢夺未来 AI 专家的未来。没有伟大的学者,谁来培养下一代创新者?
5.2 AI 大学
专门致力于人工智能的新机构正在世界各地推出。在阿拉伯联合酋长国,新的人工智能大学于去年成立。MBZUAI 是世界上第一所研究生水平的研究型人工智能大学。人工智能大学由哈佛大学和加州大学洛杉矶分校共同创建,是一个机器学习和人工智能培训的在线项目。
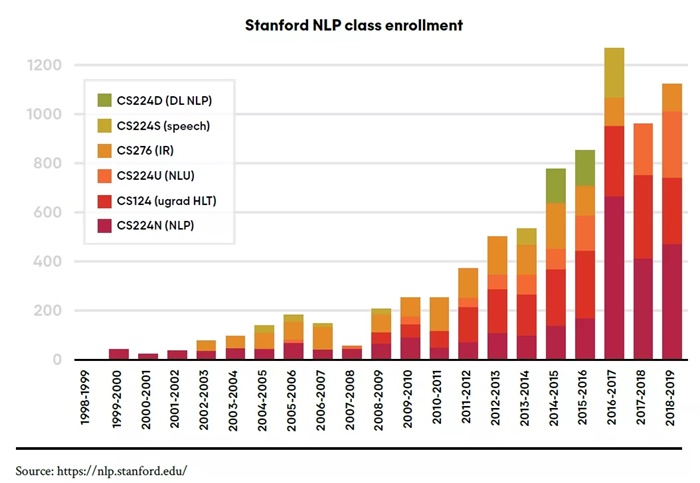
图 | 斯坦福大学自然语言处理课程的注册人数是 2004 年的 10 倍
5.3 对 AI 的需求正在增长
多年来,人工智能人才的需求超过了供应。在美国,去年与人工智能相关的职位发布比与人工智能相关的职位查看多近三倍。虽然学校正在增加项目,增加招生,增加班级,但对人工智能技能的新需求太多,训练有素的工人远远不够。随着需求的增长,招聘过程需要更长时间,成本也越来越高。
5.4 企业 AI 实验室
人工智能实验室遍布世界各地,集中在北美、欧洲和亚洲。Facebook、谷歌、IBM 和微软运营着 62 个致力于人工智能研发的实验室,其中大多数在美国以外,因为可以接触到人才。
5.5 面试 AI
识别系统现在可以用来观察你被面试的情况,并衡量你的热情、坚韧和沉着。算法分析数百个细节,如你的语气,你的面部表情和你的习惯,以最好地预测你将如何适应一个社区的文化。
6. AI 与创造性
6.1 辅助创造力
生成性敌对网络 (GANs) 的能力远远超过生成深度伪造视频。研究人员正在与艺术家和音乐家合作,以产生全新的创造性表达形式。从合成非洲部落面具到建造幻想、虚构的星系,人工智能被用来探索新的想法。
6.2 用于内容的生成算法
“野蛮司法” 在 YouTube 上播出,由一名合成记者弗 Fred Sassy 担任主角,他看起来很像前总统特朗普,只是声音和发型不同,足以逃避法律挑战。剧集中出现了 Gore,Mark Zuckerberg,Jared Kushner 和其他人的虚假人物。
6.3 从短视频生成虚拟环境
Nvidia 正在教人工智能从短视频剪辑中构建逼真的 3D 环境。该方法建立在以前对 GANs 的研究基础上。自动生成的虚拟环境可以用于幻想和超级英雄电影,并可以降低电视制作和游戏开发的成本。
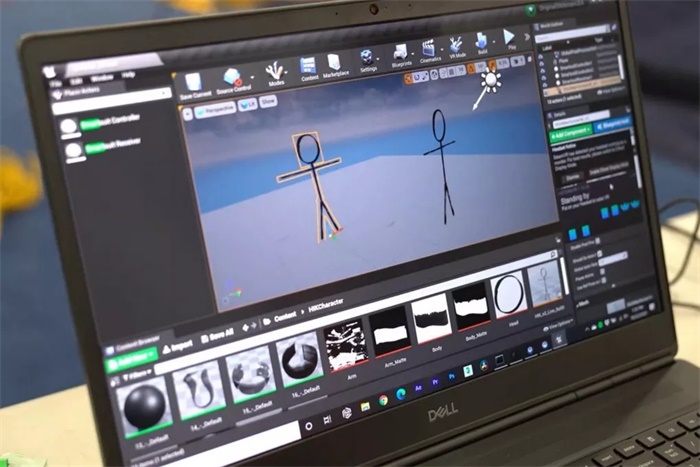
图 | 创意工作室 SoKrispyMedia 制作以战斗中的棍形人物为特色的短片。它依靠实时渲染来获得逼真的结果 (来源:Nvidia)
6.4 自动化版本控制
总部位于瑞士的塔梅迪亚的记者们在他们国家 2018 年的选举中,一个名为鸢的决策树算法生成了自动化的文章,详细描述了私人媒体集团旗下 30 家报纸覆盖的每个城市的投票结果。这些文章有一个特殊的署名,提醒读者它们是由一种算法写的。随着更多实验的进行,我们预计新闻和娱乐媒体公司将开发同一内容的多个版本,以覆盖更广泛的受众或大规模制作大量内容。
6.5 自动语音克隆和配音
类似人工智能和描述性人工智能在内的人工智能公司的承诺使得克隆声音成为可能。这意味着很快你可能会在电影中看到像 Phoebe Waller-Bridge 这样的明星,还会听到她用自己的声音说葡萄牙语。然而,这项技术显然有黑暗的一面,导致了语音诈骗的出现。

图 | 自动点唱机是一个神经网络,它产生音乐,包括初级歌唱,作为各种流派和艺术家风格的原始音频
6.6 自动环境噪声配音
人们一直在训练计算机观看视频,并预测我们物理世界中相应的声音。这项研究的重点正在麻省理工学院的计算机科学和人工智能实验室进行,应该有助于系统理解物体在物理领域是如何相互作用的。许多项目正在进行中,以使自动生成声音、视频甚至故事情节变得更加容易。
7. AI 与安全
7.1 AI 民族主义
政府正在对并购和投资活动实施新的限制,以确保公司开发的人工智能不会帮助外国对手。去年,美国参议院提出的一项两党法案被称为 “永无止境边境法案”,该法案明确将人工智能界定为美国和中国之间的一场竞赛。

图 | 美国众议院通过了永无止境边境法案
7.2 国家 AI 战略
新一波国家将在 2021 年和 2022 年推出国家人工智能战略。中国通过了新一代人工智能发展计划,设定了新的基准,要在 10 年内成为世界上占主导地位的人工智能玩家。在美国,许多公共和私人团体代表国家独立研究人工智能的未来。然而,这些努力缺乏机构间协作和协调努力,以精简目标、成果、研发努力和资金。
7.3 作为关键基础设施的 AI
政府研究人员正在探索引领关键系统应用人工智能开发的方法:公路和铁路运输系统;发电和配电;和消防车等公共安全车辆的路线预测。人们不再回避人工智能系统,而是对使用该技术来预防灾难和提高安全性产生了新的兴趣。
7.4 基于国家的防护和法规
从自动驾驶汽车事故到通过虚假信息活动干扰选举,再到通过面部识别和自动监控增强的政治镇压,过去几年的重大事件极大地缓解了人工智能的危险。对于一项触及人类方方面面的技术来说,现在几乎没有防护存在,各国都在竞相开发和发布自己的人工智能战略和指南。
7.5 监管 DeepFake
美国和其他地方将在 2021 年出台新的措施来监管深度假货的生产和分销。夏威夷州议会的一项法案试图禁止未经授权的 DeepFake 应用程序和工具。如果通过,DeepFake 将被视为 C 级重罪。这些倡议可能会遇到禁止 DeepFake 侵犯言论自由权的争论。
7.6 让 AI 自我解释
计算机科学家、记者和法律学者越来越担心人工智能系统不应该如此神秘,监管机构正在密切关注。总的来说,必须克服一些挑战。要求人工智能透明可能会泄露公司的商业秘密。要求系统在工作时解释他们的决策过程也会降低输出的速度和质量。在未来的几年里,不同的国家可能会颁布新的规定要求 AI 自我解释。
7.7 新战略技术联盟
国家间新的战略技术联盟将有助于推动未来的研发,但也可能使现有的地缘政治联盟紧张或加剧紧张局势。可能的合作伙伴包括美国、德国、日本、印度、韩国、英国、法国和加拿大 —— 剩下中国和俄罗斯将分别合作。后两个国家已经宣布了卫星和深空探测技术联盟。

图 | 网络战将在未来十年改变战争艺术
7.8 新型军工联合体
在过去的几年里,美国一些最大的人工智能公司已经与军方合作,推进研发并提高效率。事实上,没有外部公司的帮助,公共部门无法推进其技术。另外,还有很多钱可以赚。
7.9 算法战争
未来的战争将以代码形式进行,使用数据和算法作为强大的武器。当前的全球秩序正在由人工智能塑造,在人工智能研究方面领先世界的国家在开发至少包括一些自主功能的武器系统。
8. 中国的 AI 规则
8.1 中国人工智能现况
如果你认为中国是一个复制而不是创新的国家,那就再想想。中国是人工智能的全球领导者,在许多领域都取得了巨大的进步。企业和政府已经合作制定了一项全面的计划,到 2030 年使中国成为世界主要的人工智能创新中心,并且已经朝着这个目标取得了重大进展。
中国比西方有着不可思议的优势。这也给了中国三大公司百度、阿里巴巴和腾讯超能力。总的来说,它们被称为最佳可得技术,它们都是该国资本充足、高度组织化的人工智能计划的一部分。
中国人的回报不仅仅是典型的投资回报,中国公司也期待知识产权。总部位于中国的人工智能初创公司现在占全球人工智能投资的近一半。
8.2 受中国教育的研究人员突起
总部位于保尔森研究所 (Paulson Institute) 的智库宏论道 (MacroPolo) 的一项新研究显示,受中国教育的研究人员主导了著名的国际人工智能会议神经科 (NeurIPS) 接受的论文。宏论道促进了美中之间的建设性合作。近三分之一的论文来自中国 —— 比任何其他国家都多。

图 | NeurIPS 接受的论文有近三分之一的论文来自中国
9. AI 与社会
9.1 伦理冲突
2020 年 12 月 2 日,谷歌伦理人工智能团队的共同创始人 Timnit Gebru 发布了一条推特,说她被解雇了。她因在偏见和面部识别方面的开创性研究而闻名,在更广泛的人工智能社区中广受尊重。
Facebook 成立了一个独立的监督委员会,有权否决内容审核准则,甚至否决马克・扎克伯格本人。2021 年 1 月,该委员会对有争议的内容做出了第一次裁决,推翻了它所看到的五起案件中的四起。但 Facebook 上每天都有数十亿条帖子,还有数不清的内容投诉 —— 这意味着监督委员会以传统政府的速度运作。我们预计 2021 年会有更多的道德冲突。

图 | 算法偏见的先驱研究者 Timnit Gebru
9.2 环境监测
关起门来发生的事情可能不会保密太久,高管们应该警惕新的环境监控方法。麻省理工学院的科学家发现了如何使用计算机视觉来跟踪室内的数据,这对从事敏感项目的公司来说可能不是好消息。从事信息安全和风险管理的人应该特别注意计算机视觉的进步。
9.3 市场整合
随着人工智能生态系统的繁荣,大量收购也意味着整合。大公司现在早在初创公司成熟之前就将其抢购一空。只有九家大公司主宰着人工智能领域:美国的谷歌、亚马逊、微软、IBM、Facebook 和苹果,中国的百度、阿里巴巴和腾讯。
在投资方面,高通、腾讯、英特尔投资、谷歌风险投资、英伟达、Salesforce、三星风险投资、阿里巴巴、苹果、百度、花旗和智能手机为增长提供了大量资金。
9.4 分散
人工智能生态系统跨越数百家公司。他们正在构建网络基础设施、定制芯片组和消费应用等。与此同时,大量的政策团体、倡导组织和政府正在制定指导方针、规范和标准以及政策框架,希望能够指导人工智能的未来发展。因此,生态系统在两个方面是分散的:基础设施标准和治理。
9.5 AI 偏见问题
众所周知,人工智能有一个严重的多方面的偏见问题。随着计算机系统越来越擅长决策,算法可能会将我们每个人分成对我们来说没有任何明显意义的组,但可能会产生巨大的影响。
越来越多的数据在你不知情的情况下被收集并出售给第三方。随着时间的推移,这些偏见会自我强化。随着 AI 应用越来越普遍,偏向的负面影响会更大。
9.6 有问题的培训数据
开发人员社区中遇到了一些挑战。即已经很难从真实的人那里获得真实的数据来训练系统,并且随着新的隐私限制,开发人员选择更多地依赖公共的数据集,这些数据集可能存在问题。
9.7 AI 捕捉欺骗行为
AI 正被用来捕捉欺骗行为。ECRI 研究所的 CrossCheq 使用机器学习和数据分析来寻找招聘过程中的夸张和误导信息。哥本哈根大学的研究人员创建了一个机器学习系统,以 90% 的准确率发现论文中的作弊行为。
9.8 针对弱势群体的算法测试
经过正确训练的机器学习系统可以帮助找到失踪的儿童并发现虐待行为。问题是,这些系统使用来自弱势群体的数据来进行培训。图像识别是一个特别棘手的挑战,因为研究人员需要大型数据集来完成他们的工作,经常是未经同意使用图片。
9.9 AI 故意隐藏数据
斯坦福大学和谷歌的研究人员发现,旨在将卫星图像转化为可用地图的人工智能隐瞒了某些数据。最初,他们使用了一张网络没有看到的航拍照片。最终的图像看起来非常接近原始图像。但是在更深入的研究中,研究人员发现原始图像和生成图像中的许多细节在人工智能制作的地图中是不可见的。事实证明,系统学会了将原始图像的信息隐藏在它生成的图像中。
9.10 未曝光的 AI 事故
2018 年和 2019 年众多 AI 相关事故中,只有少数成为头条。但还有无数次没有导致死亡的事件公众并不知道。目前,研究人员没有义务报告涉及我们数据或人工智能过程的事故或事件,除非违反了法律。
虽然大公司必须告知消费者他们的个人数据是否被盗,但它们不需要公开记录算法学会基于种族或性别歧视他人的情况。
9.11 数字红利
人工智能将不可避免地导致全球劳动力的转移,导致许多行业的失业。牛津大学人类研究所的研究人员、今日未来研究所的研究人员和前美国总统候选人杨安泽都发表了概述不同版本的 “数字红利” 的著作 —— 这是公司向社会偿还部分人工智能利润的一种方式。
9.12 信任优先
人工智能系统依赖于我们的信任。如果我们不再相信他们的成果,几十年的研究和技术进步将会付诸东流。政府、企业、非营利组织等各个部门的领导者必须对所使用的数据和算法有信心。建立信任和问责制需要透明度。
此外,雇佣伦理学家直接与经理和开发人员合作,并确保开发人员本身是多样化的,代表不同的种族、民族和性别,将减少人工智能系统中固有的偏见。
人工智能在多个维度上影响着每一项业务。人工智能是大多数组织的基石,从员工自动化到数字化,再到员工分配等等。
人工智能也是创新和创造过程的添加剂。创新团队可以利用深度学习来开发新产品,了解市场,预测即将发生的事情。特别是随着无代码和低代码应用程序变得更加广泛,创新团队将为决策管理、一般性头脑风暴和产生新想法的强大方法构建强大的系统。
同时,人工智能又面临了许多风险。新法规可能会抑制研究、创新和产品开发。地缘政治紧张和人工智能民族主义将开始以新的方式引导外国投资。面部识别中的偏见应该是大家都关心的。应开发风险模型来确定可信的近期情景,以便领导者能够相应地调整策略。
最后,这份报告还涵盖了包括 5G、区块链在内的其他众多领域的技术趋势,但是由于篇幅所限,在这里不能一一翻译整理。
(原报告篇幅较多,解读内容难免有纰漏,请大家多指正)
资料来源:
https://futuretodayinstitute.com/trends/
编者按:本文转载自微信公众号:学术头条(ID:SciTouTiao),作者:阳光

AI 让网络安全更智能
